.svg)
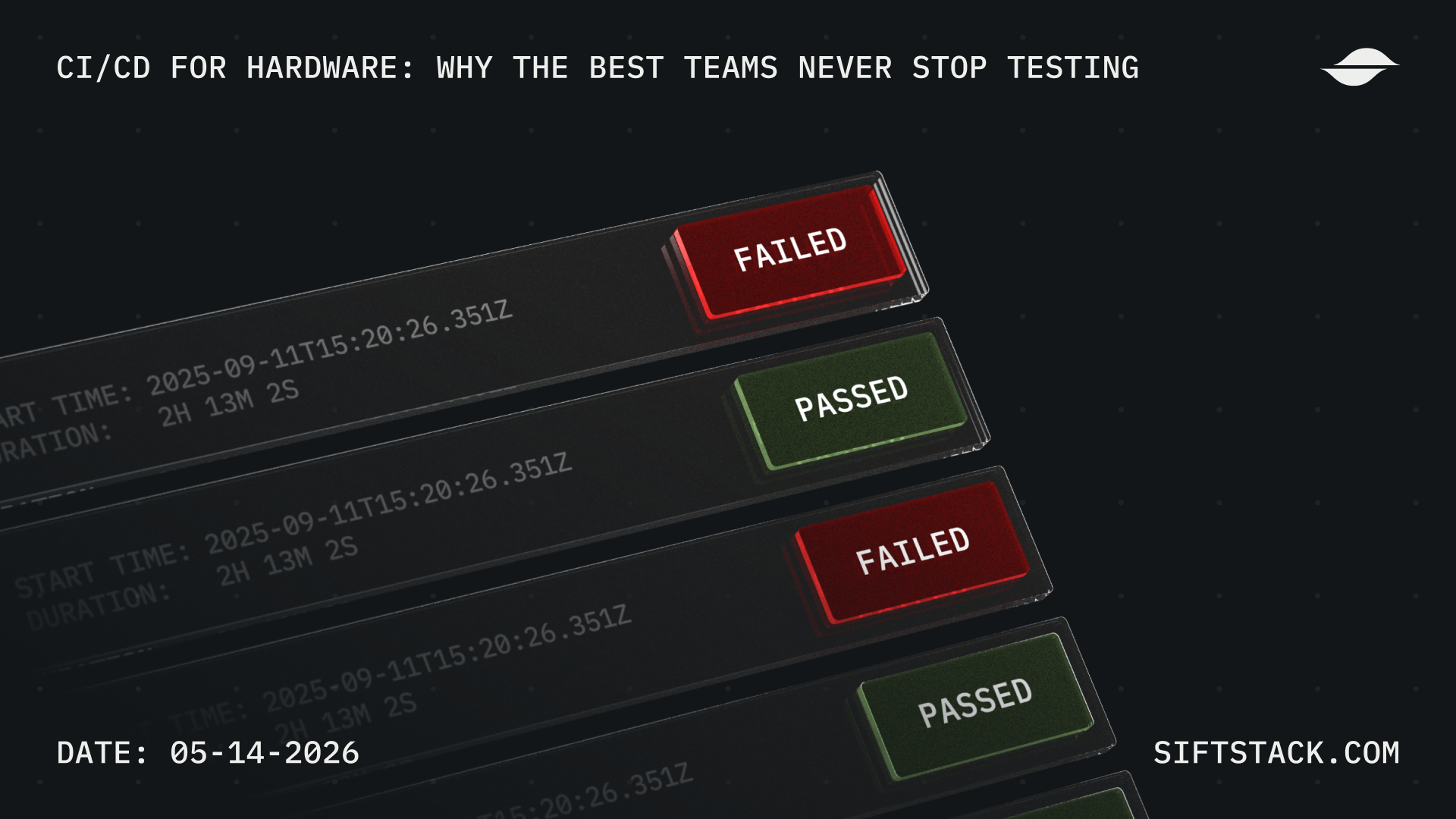
When a rocket engine fails, an engineer downloads a CSV, runs a Python script written by someone who left the company a year ago, and spends the next two hours trying to remember what the channel names mean. When a web application breaks, an engineer opens a trace and finds the problem in minutes.
Software solved it with tracing, logging, and metrics. Hardware never got its equivalent. Sift is building it.
The physical world generates some of the most complex data on earth: high-frequency sensor streams, multi-modal telemetry, pressure spikes that last microseconds, vibration signatures that only make sense when cross-referenced against audio and thermal data from the same test. None of the platforms built for software observability were designed for this. They weren't designed to handle data at 10kHz, let alone align timestamps across five vehicles running on independent clocks. They weren't designed to keep petabytes of historical test data queryable without costs that break a program budget.
Sift closed a $42M Series B led by StepStone Group, with GV (Google Ventures) as our largest investor, bringing total funding to $67M. We built Sift because that gap between what the machines know and what the engineers can see has been treated as normal for too long.
Built by Engineers Who Have Felt the Problem
We started Sift to build the infrastructure we needed while building human-rated spacecraft and the largest satellite constellations in history at SpaceX.
Here's what it looks like in practice. Something goes wrong on a test stand. In the old world, you're pulling data from three different systems, writing a one-off script to align timestamps, and hoping the engineer who set up the channel mapping documented it somewhere. In Sift, the sensor data, audio, video, and logs from that test are already in one system, under one schema, queryable in sub-second time. You're not wrangling data. You're interacting with it.
That same data from your qualification campaign two years ago? Also queryable, at the same speed, without the cost structure of keeping everything in hot storage. Sift decouples compute and storage so historical data stays accessible for the life of the program.
And because every data type, across all 11+ hardware-native formats, lands in a structured schema, the data isn't just readable by engineers. It's readable by models. That's the difference between training anomaly detection on real test data versus training it on synthetic datasets because your actual telemetry was locked in CSVs on someone's laptop.

The Programs Running on Sift
Astranis operates a fleet of microGEO communications satellites. Sift is the central data layer for their test and flight operations, from board-level hardware testing through production testing to on-orbit mission ops. It's the central point of their data operations ecosystem, powering data needs from thermal testing through production all the way to on-orbit mission ops. Rather than stitching together separate tools for each use case, Astranis runs Sift as the shared data layer underneath nearly every front end and workflow across the company.
Impulse Space runs satellite operations with a team of four. Before Sift, that meant manually checking the satellite every two hours, around the clock. Now over 100 live alert rules on LEO-3 push straight to PagerDuty. Seconds from anomaly to alert. Sift is what makes a four-person ops team viable.
K2 Space brought Sift in from day zero rather than tax a small team with brittle internal tooling. They've gone from 10MB of test data over the course of a summer to tens of terabytes per week, with tens of thousands of channels monitored in real time at sub-second latency. Investigations that used to take 4 to 8 hours of MATLAB scripting now take less than one.
CX2 builds electronic warfare systems for spectrum dominance. Before Sift, field testing cycles stretched across days: run a test, manually compile data, analyze with CSVs and Python scripts, then iterate. Sift compresses that loop into hours.
Parallel Systems is running autonomous freight vehicles on live rail corridors with Sift monitoring test and operational data, with rules executing nightly via GitHub Actions and regulatory evidence compiled across three jurisdictions.

Why Now
Test cycles that used to take months are being compressed into weeks. AI is getting embedded into validation workflows, anomaly detection, and regression analysis. Not as a future roadmap item but as a current engineering requirement on active programs.
That acceleration has a dependency that isn't being talked about enough: AI for hardware only works if the data layer was built for it. A model that needs to detect an engine knock can't be trained on CSVs living on separate engineers' laptops. A tool built to generate test reports has the same problem in a different form: the data was structured for a chart, not for a model. A closed-loop feedback system that updates simulation parameters based on field behavior can't function if test data and operational data live in systems that don't speak to each other.
That's the hardware observability problem. The AI era for physical systems does not start with the model. It starts with the data infrastructure underneath it. That is what has been missing. That is what Sift is.
What Comes Next
Not a dashboard. Not a data lake. An intelligence layer: the system that knows what the machine did, when it did it, why it matters, and what comes next. One that makes the historical record queryable for the life of the program, makes AI-assisted analysis tractable instead of theoretical, and makes the knowledge that lives in a veteran engineer's head something the organization can actually retain.
Trusted by Astranis, K2 Space, Parallel Systems, Astrolab, and undisclosed enterprise defense programs. 70 employees today. Doubling again with this round. All from our new headquarters in Marina Del Rey.
.avif)
The infrastructure layer between AI and mission-critical hardware has been missing. We are building it.




.avif)