
.svg)
Your team is weeks from a milestone release when a late-stage test surfaces a subsystem anomaly that passed earlier reviews. The fix isn't isolated and cascades into adjacent systems. Unfortunately for you, the test environment you need is booked by another program. Manually reviewing months of telemetry to understand what changed just isn't feasible in the time you have. So the release slips and the budget conversation gets harder. To add insult to injury, the next program in the queue starts late.
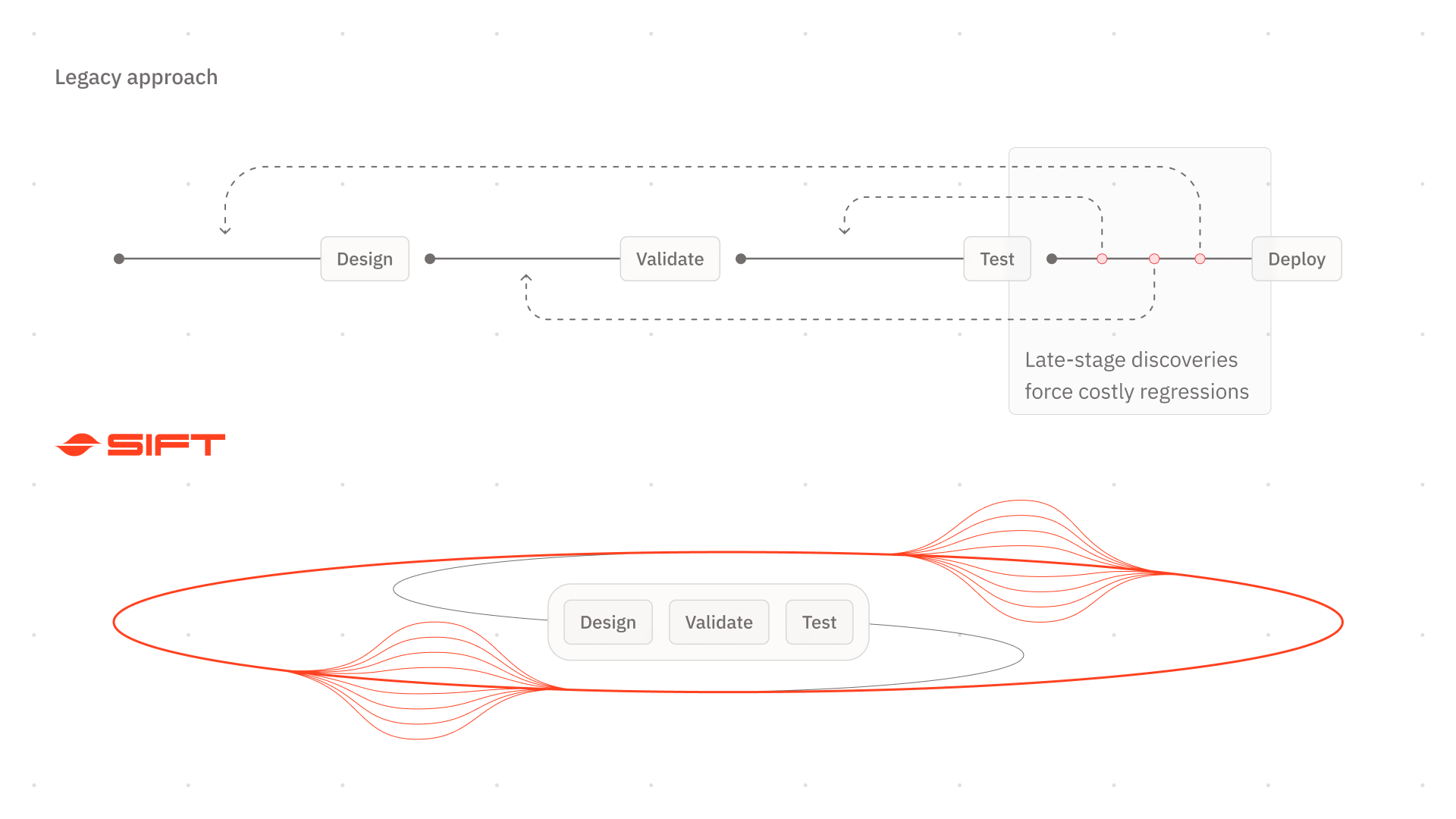
Legacy approaches phase testing when you can least afford it - and rework can be 100x more expensive
Whether you're building autonomous vehicles, industrial robots, turbines, or satellites, this story plays out the same way. The legacy approach treats testing as a phase, not a system. Requirements are defined up front, components are designed and built, and then everything gets validated in a compressed window at the end. Limited access to high-fidelity test environments creating scheduling bottlenecks. Teams compensate with manual validation that forces spot-checking instead of holistic review. Issues that could have been caught iteratively pile up instead and the cost of rework to address each fix multiplies the later it's discovered.
These risks are compounded by how quickly machines themselves are evolving. Modern hardware systems are software-defined, autonomous, and getting smarter all the time. Validating against a fixed set of scenarios at a single point in time is not an accurate reflection of how these systems actually operate. The machines have outgrown the legacy testing models that were supposed to validate them.
The result is a vicious, self-reinforcing loop: more risk concentrated at the end, more burden on bottlenecked test environments, more manual review that can't keep pace, and more late-stage surprises that erode confidence and blow timelines.
But none of this is inevitable. Another industry faced the same problem and solved it.
Software teams solved this decades ago. Hardware teams can too.
In software development, continuous integration and continuous delivery (CI/CD) transformed how teams ship products. CI/CD is the practice of automatically building, testing, and validating every change as it's made, rather than batching changes together and testing them all at the end. Instead of a quarterly release that bundles hundreds of changes and hopes nothing breaks, software teams merge small updates continuously, with automated tests running against each one. The result: smaller batches of risk, faster feedback, and far fewer surprises at release time.
This approach proved so effective that it became the standard across the software industry. The question is why hardware teams are still stuck in the legacy approach.
The answer, until recently, was tooling. Software CI/CD runs on infrastructure built specifically for code: version control systems, automated test runners, deployment pipelines. Hardware telemetry is fundamentally different. It's high-frequency, high-cardinality, time-series data streaming from physical sensors on real machines in the real world. The tools that power software CI/CD were never designed to handle it. But the principle itself is sound, and the teams that have found ways to apply it to hardware are already pulling ahead.
Faster iteration reduces risk, and launch vehicle programs prove it at scale
Consider the contrast playing out in one of the most demanding engineering domains on the planet: space. Legacy launch vehicle programs, like NASA’s SLS, followed the traditional playbook: exhaustive upfront planning, long integration cycles, and late-stage validation. The "failure is not an option" mindset demands flawless execution, but the result has been cost overruns measured in billions of dollars and schedule slips measured in years.
The new generation of launch vehicle programs, like SpaceX’s Starship, takes the opposite bet. A high takt rate (the pace at which complete units move through production, a concept borrowed from lean manufacturing) with rapid build-test-learn cycles. Not every unit is perfect, but issues surface earlier, get fixed faster, and systemic risk decreases over time.
This isn't unique to launch vehicles. Any team building complex machines can apply the same principle: smaller, more frequent releases carry less risk per iteration. Each release validates a smaller set of changes. Anomalies are easier to isolate. The foundation underneath this approach is "test like you fly," born from real mission failures where hardware encountered operational conditions for the first time in the field. But realism alone isn't enough. You also need frequency and traceability. CI/CD for hardware means defining validation at design-time, executing it continuously at run-time, and compounding insights in post-processing.
So why haven't more hardware teams made this shift?
Adoption isn’t as easy as adopting a new methodology. Continuous validation demands purpose-built infrastructure and tooling. You can't debug with dashboards alone. You can't trace causality across a fleet with checklists and screenshot annotations. Monitoring is not the same as observability. Continuous validation requires structured, trustworthy data from the moment it's collected: ingestion, normalization, storage, and querying in a single system. Not bolted-on analytics after the fact. Not another visualization layer on top of fragmented telemetry. Continuous testing without structured data and analysis isn't progress, it's noise.
Sift's Rules codify engineering knowledge into automated, real-time checks
Sift was started to solve this exact problem. In Sift, Rules codify engineering expertise into automated, real-time validation, replacing ad hoc scripts, manual anomaly detection, and tribal knowledge that lives in someone's head instead of in the workflow. It’s what’s needed to make CI/CD for hardware a reality.
- Capture what your best engineers know, and turn it into institutional knowledge. Engineers define expected behavior (thresholds, tolerances, telemetry patterns) as rules during design. That expertise lives in the workflow itself, not in documentation that drifts from reality. When someone leaves or a program changes hands, the knowledge stays.
- Get instant feedback on every change, not a surprise at the end. Every hardware or software update is continuously evaluated against predefined rules. Engineers see deviations the moment they occur, so issues get resolved while there's still time to act, not during the final test window when the schedule has no margin.
- Validate behavior over time, not just individual thresholds. Rules hold state across a run, functioning like unit tests for the physical world. Instead of catching a one-off spike and hoping it doesn't recur, engineers can reason about trends, sequences, and patterns that only emerge over time.
- Know exactly what changed between builds without manual diffing. Regressions surface automatically across runs. When teams are releasing frequently, this is the difference between confidently shipping an update and spending days tracing a subtle behavioral change back through logs.
- Write a rule once, apply it across the fleet. A rule defined for one unit validates behavior across every similar unit in production. One definition scales to the entire fleet without duplicating effort, so engineers spend time refining rules, not rewriting them for each asset.
- Trace an anomaly to its root cause in minutes, not hours. Flagged anomalies link directly to the underlying telemetry data. Engineers go straight from "something looks wrong" to "here's why" without hunting through logs across disconnected systems.
All of these features are on top of a purpose-built infrastructure that has kept hardware’s high-frequency, high-cardinality data needs in mind since day zero. Teams that use Sift are able to put continuous validation into practice and see the benefits immediately.
Catching anomalies earlier cuts costs by orders of magnitude
The cost-of-quality principle known as the 1-10-100 rule makes the economics clear: a defect caught at design costs $1 to fix, $10 at production, and $100 or more after deployment. In hardtech, those ratios get steeper. Post-deployment fixes can mean field recalls, regulatory action, or mission failure. Rules shift detection to design-time, moving teams toward the $1 end of that curve with every validated iteration.
With continuous automated validation in place, each release carries less risk, which means you can release more often. Sift customers are running test cycles four times faster than they otherwise would. But speed alone isn't the point. When teams pair faster iteration with systematic analysis, capturing the right telemetry and feeding insights back into simulations, more frequent releases produce better data. Better data improves simulations. Better simulations make every subsequent test more effective. This isn't a one-time efficiency gain; it compounds.

The contrast between legacy and modern launch vehicle programs illustrates where these two approaches end up at scale. One concentrates risk at the end and pays for it in billions of dollars and years of schedule. The other distributes risk across rapid iterations and drives costs down with every cycle. Same domain. Fundamentally different development philosophy.
Engineers stop spending their time on manual review overhead and start spending it on design improvements and risk mitigation. High-fidelity test environments stop being the bottleneck because issues are caught earlier, in lower-fidelity environments. The path from validated design to deployment becomes predictable rather than reactive.
Validate continuously, release confidently
Hardware development doesn't have to be trapped in long, fragile release cycles. The teams pulling ahead are the ones that treat validation as infrastructure (continuous, automated, and compounding) not as a phase that happens at the end.
Sift makes that shift concrete: codified engineering knowledge, enforced automatically, from design through deployment. Every rule is a unit of institutional expertise that runs in real time, scales across fleets, and creates a traceable record of system confidence.
If you want your test cycles measured in hours instead of weeks, we'd love to hear from you.








