.svg)
The most expensive loss is the kind you don't measure.
The biggest risk in hardware engineering isn't the one that shows up in a fault tree. It's the slow, invisible loss of the judgment and context that experienced engineers carry in their heads.
This isn’t the kind of knowledge you can find in a spec or a requirements document. We’re talking about the engineer who knows why a particular sensor threshold was set at 4.2V instead of 4.5V. The test lead who remembers that a specific actuator behaves differently under thermal cycling after 200 hours. The systems engineer who can look at a telemetry trace and immediately spot the signature of a problem the team solved three years ago.
That knowledge is the difference between an organization that moves with confidence and one that rediscovers its own lessons at enormous cost.
The compounding math makes this urgent. Even modest attrition, say 10% per year, means an organization loses nearly its entire original engineering team within a decade. Each departure doesn't just remove a person. It removes the contextual judgment that made their knowledge actionable: the reasoning behind decisions, the subtle patterns they'd learned to recognize, the failure modes they'd seen before.
Left unchecked, this erosion is silent and cumulative. By the time leadership notices, the gap is already deep.
Attrition is how proven systems become black boxes.
When organizations recognize the risk of knowledge loss, the instinct is to lock things down. Freeze the design. Write more documentation. Build more dashboards. If the system works, don't touch it.
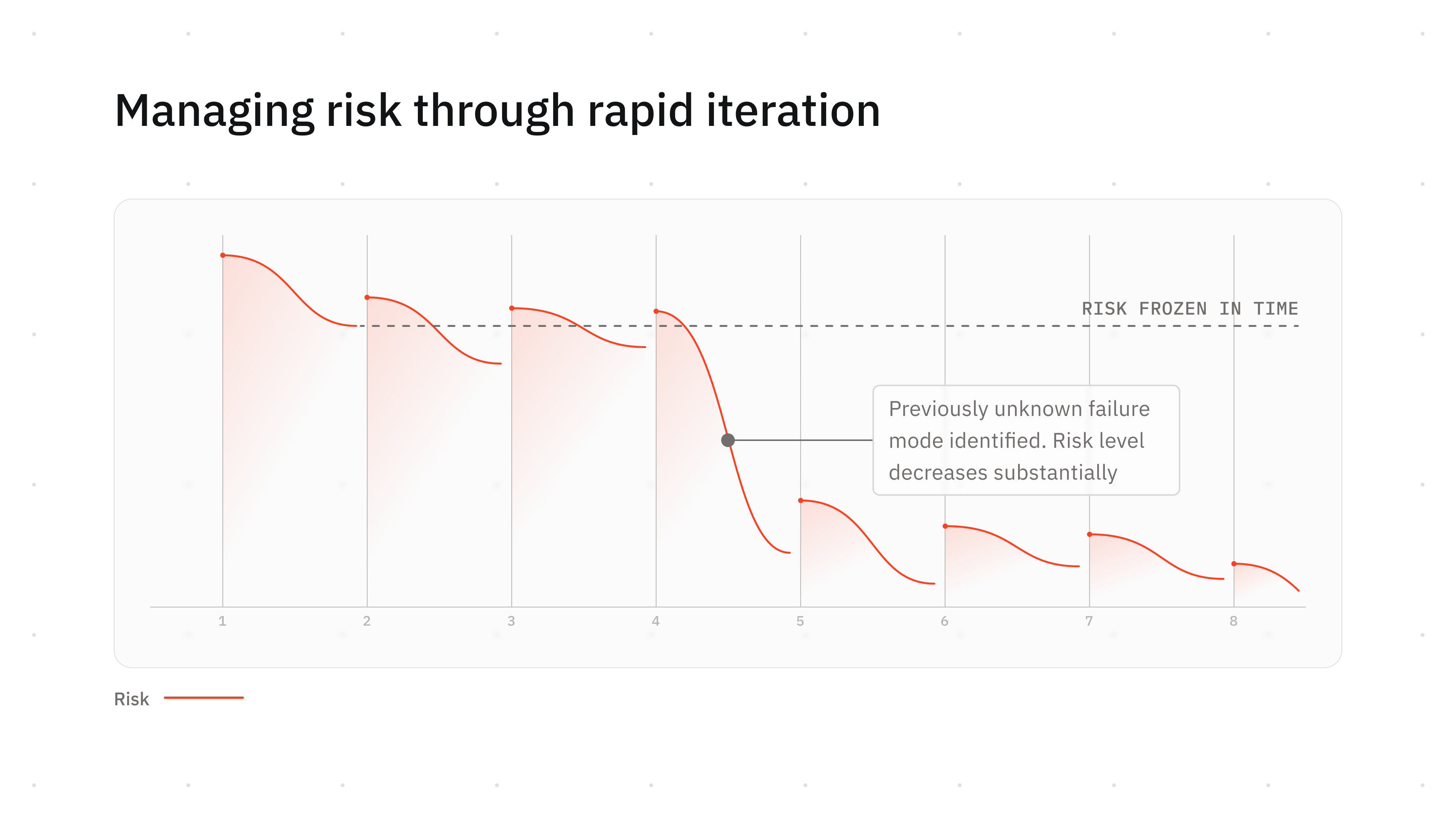
This is the "flight heritage" approach and it has a long history. The Russian space program took this path with the Soyuz vehicle in the 1960s. After a series of successful flights, they declared the design proven and essentially froze it. The logic was straightforward: a working system is a reliable system.
Decades later, when the Soyuz encountered unexpected issues, the program confronted a stark reality. None of the original engineers who understood the vehicle's performance envelope were still around. What had been a well-understood system was now an inherited black box. The people who could have diagnosed and resolved the problem with confidence were gone, and their knowledge had gone with them. Not just the specifications, but the reasoning: why particular margins were chosen, what specific thermal signatures meant, which failure modes were the real constraints versus the conservative ones. That decision context is what would have let the next generation evolve the system with confidence instead of fear. In other words, preventing change doesn’t ensure reliability.
This pattern extends far beyond spacecraft. Any organization that treats "proven" systems as untouchable creates the same vulnerability. The knowledge needed to maintain, troubleshoot, and evolve those systems quietly evaporates while leadership assumes it's preserved in documents and dashboards.
Traditional monitoring tools reinforce this trap. Static monitoring generates endless uncorrelated alerts. Insights live in one-off dashboards that multiply without creating shared understanding. Documentation sits in scattered wikis and spreadsheets, detached from the telemetry workflows where knowledge is actually created. Engineers end up drowning in data while starving for context, and the gap between "what happened" and "why it matters" keeps widening.

Reliability means managing risk through change.
SpaceX, under Hans Koenigsmann's leadership, took the opposite approach: continuous iteration, aggressive testing, and treating every flight as an opportunity to deepen the organization's collective understanding. The lesson isn't that freezing is always wrong. It's that reliability without retained knowledge is an illusion. Reliable systems are systems that are both deeply understood and have managed risk while continuously evolving. The teams that test more frequently build deeper institutional memory and therefore build more reliable systems, provided they can capture their learnings as fast as they discover them.
That's the real bottleneck. Most engineers aren't unwilling to share what they know. But when documentation requires jumping to a wiki, creating a new page, formatting it correctly, and linking it back to the relevant data, most engineers skip it. The intent is there. The process defeats it. Knowledge capture only works when it lives inside the workflow, not alongside it.
Operationalizing institutional knowledge capture with Sift.
Sift is a unified observability platform purpose-built for the gap between traditional IT monitoring and what hardware engineering actually demands: high-frequency telemetry at thousands of samples per second, dynamic schemas that evolve with every design iteration, time-aligned data across subsystems with sub-nanosecond precision, and retention measured in years, not days. Built on Apache Parquet, Sift handles the longitudinal queries that matter most to hardware teams, like "what did this engine look like the last 1,000 times it fired?"
But the data infrastructure is only the foundation. What makes Sift a bedrock for institutional knowledge is how it embeds knowledge capture directly into the engineer's primary workflow.
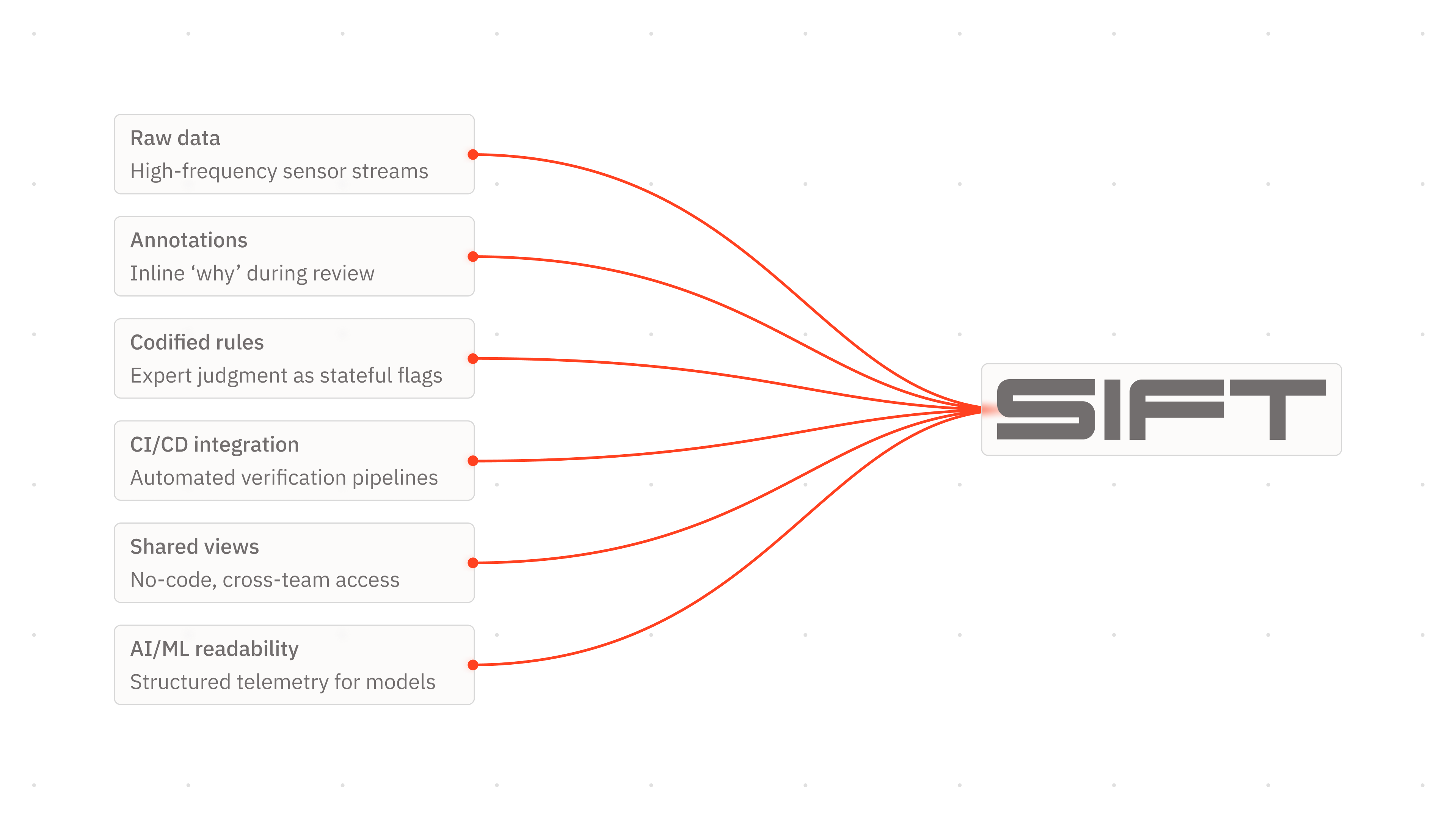
Context and data live together. During data review, engineers annotate telemetry in-line, capturing the "why" alongside the "what." Not in a separate wiki or a disconnected document, but right next to the data itself, like in-line code comments that stay contextually relevant and discoverable. When another engineer encounters a similar signal pattern six months later, they see not just what happened, but why it mattered and what the team learned from it.
Your best engineer’s judgement raises the floor. As insights accumulate, engineers codify them into stateful rules that automatically flag known patterns across future datasets. What one engineer learned from a single anomaly becomes organizational judgment, applied consistently to every test, every mission, every review. Sift also integrates directly into CI/CD pipelines, so these rules run as part of automated verification and validation, catching regressions before they reach production.
Shared insights compound learnings. Shared views ensure that this knowledge isn't locked in one engineer's workflow or one team's folder. Every engineer gets access to the collective understanding. And because Sift's instrumentation requires no code, the engineers with the deepest domain expertise, not just those comfortable with Python or SQL, can directly encode their knowledge into the system. Sift also makes hardware telemetry AI-readable, turning years of accumulated machine data into a structured foundation that AI and ML models can reason over.
The result is a living knowledge base that grows more valuable with every test and every review. Knowledge stops depreciating and starts compounding.
When knowledge compounds, everything accelerates.
When institutional knowledge compounds instead of decays, the effects ripple across the organization.
New engineers ramp faster. Instead of starting from scratch or relying on hallway conversations with senior staff, they explore real datasets enriched with expert annotations and codified rules. The learning curve flattens because the organization's history is accessible, not locked in someone's head.
Test cadence increases. Automated data review, powered by the rules and patterns the team has built over time, removes the bottleneck that traditionally limits how fast teams can iterate. More tests, faster feedback, deeper understanding. This is what "test as you fly" looks like when the tooling keeps pace with the testing.
Attrition becomes manageable. Each departure is still a loss, but it's no longer existential. The departing engineer's judgment lives on in the annotations, rules, and shared context they contributed. The next engineer inherits years of accumulated insight, not just a spec.
This is the difference between an organization where knowledge is a fleeting asset and one where it's bedrock. Preserved, shared, and compounding over time. The most reliable hardware isn't built by organizations that avoid change. It's built by organizations that embrace change with confidence, because every lesson learned is captured, accessible, and working for the team long after the person who learned it has moved on.
Talk to us about how your team's institutional knowledge can become an enduring organizational asset.